In recent years, more companies have adopted advanced solutions that leverage emerging technologies like artificial intelligence and machine learning to organize and analyze agreements. Contracts are, at their core, what govern a relationship between two entities. They shore up compliance, help spot unrecognized opportunities, and prevent missed obligations. By using AI technology, companies can reduce both contract risk and cost by automating repetitive and arduous tasks. The Harvard Business Review estimates that inefficient contract processes can result in firms losing between 5% to 40% of a contract’s value – value that can be retained with AI-based contract management and contract analytics.
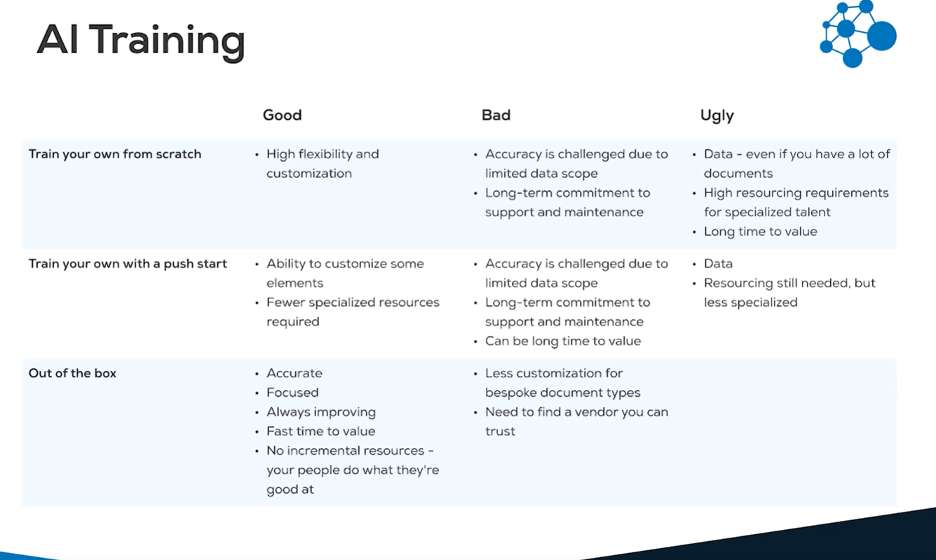
Although, traditional AI/ML training may not be the best or most efficient approach for most companies utilizing contract management software. Proper AI training requires:
- expert data science skills
- dedicated time
- an enormous contract volume
- deep learning technologies
- endless varieties of data consistently updated and maintained.
ThoughtTrace, by comparison, takes a unique approach to model development fueled by supervised AI, subject-matter-expertise, and community-driven insights that we believe to be a true differentiator for our customers. Our software works out-of-the-box, and customers see time-to-value in as little as one week.
How Traditional AI Training Works
(Disclaimer: In this short blog, we will highlight a couple of key considerations that go into this extremely complex process.)
Skyrocketing computing power and the use of deep learning have significantly increased the number of tasks which trained AI can now perform. Previously, the only option people had was manually scanning through a contract for specific information or clauses (or paying someone else to do this, which was expensive and slow). Today, AI is used to recognize different types of documents, automatically classify them, extract clauses and provisions, and conduct fast and intelligent search. Essentially, knowledge-workers can use this ability to take HUGE reading problems and make them manageable.
Even with a lot of internal documents at your disposal, the act of curating data for an AI model “that reads” is not a trivial undertaking. There is a high resourcing requirement for specialized talent, and the time-to-value is typically very long, ranging from 6-months to over a year depending on the amount of money and people thrown at the problem. Read further to learn how it works, some key considerations, and other options.
Input the Data
The first step in AI training involves data – lots of unstructured document data. The model needs sufficient data to become knowledgeable about what certain contracts contain in a variety of formats and terms. In practical terms, this means scanning physical documents and contracts, or importing digital files and deploying optical character recognition to turn the image of characters into actual characters of text. AI also needs a large variety of contracts to become familiar with all the different contingencies your business might encounter. Without a large quantity and variety of data, accuracy will be limited due to data scope.
In addition, the documents and contracts fed into the model need to be properly marked up for training. Contracts should be annotated so that the model can learn to identify important elements such as clause headings, specific terms, and so on. This tagging is essential so that the AI knows what to pay attention to.
Develop the Model
As documents are fed into the AI, the system uses natural language processing to learn to identify the important sections of each document, customary formatting characteristics, and layout to build a model for future contract identification. The more data the AI is fed, the more accurate the model it develops.
The company using the contract software can also input additional information manually. For example, you may want to tell the AI when to use specific language or reject certain provisions. The key is to provide the model with as much information as possible, as consistently as possible to avoid confusion for future evaluations.
The Downside of Traditional AI Training for Contract Analysis
There is no question that the benefits of deploying AI for document management and other document-intensive workflows are appealing; who would turn down the opportunity to reduce cost, eliminate waste, and improve efficiency? The use of advanced technologies has the potential to democratize data access in document-laden industries like Insurance, Telecommunications, Finance, Real Estate, and Energy to name just a few. Before being mesmerized by the opportunities in deploying, don’t overlook the fact that proper AI training requires considerable resources and expertise – one or more of which your company may not possess.
It Requires Expert Precision
Regardless of the number of AI toolkits on the market, there is a high level of technical and contextual expertise required to build and maintain the models. This expertise is not limited to machine learning and AI, but entails a seamless blend of technical knowledge with deep and relevant experience in the specific industry, and the legal or contractual subject matter. The language is complex which elevates the level and consistency of training required in order to create effective models. For industries with non-standard and highly nuanced agreements, subject-matter-experts from the domain of focus will also be required to label the domain-specific data accordingly.
AI training is not a “one and done” operation. It requires a perpetual investment for fine-tuning and maintenance as the ecosystem of documents and contracts evolve with the life of the business. This may be more work than your organization is prepared to invest. It is a never-ending process as there will always be new data elements, more document types that require extraction, and overall improvements that need to be made.
The experts at ThoughtTrace spend considerable time optimizing the management of training data to mitigate model biases, scrutinize model statistics to mitigate model performance degradation, and perform other pre and post-tasks that are necessary to ensure consistency and accuracy.
It Requires a Large Volume of Data
The more data fed into an AI, the more intelligent it will be. Contract AI systems require large amounts of data, and most companies keep their document and contract information under lock and key. Most do not have a large enough number of contracts to yield accurate results. The fewer contracts you feed into the model, the less accurate the results will be.
It Requires a Wide Variety of Contract Types
The variety of data used for AI training is as important as the volume. The AI needs to see enough different types of contracts to build an inclusive predictive model. In most cases, a single company does not offer the variety needed to train the AI effectively. This, in turn, limits the AI in its ability to deal with any deviations to that contract model – and hampers your company’s ability to effectively handle any new or different business opportunities that might arise. Even huge companies with millions and millions of documents need to be careful here – in the contracts space, it’s very common for a single company to have a heavy bias towards a certain form or type of agreement. As soon as something is outside of that type of form, the whole model breaks if the AI has not been trained on a variety of different documents.
In essence, with traditional training, your AI will only learn to handle those types of documents in which you currently specialize. It won’t know anything else. If it is later exposed to a new or different type of contract, the system won’t know what to do; it will be confused, and you’ll be left with a huge reading problem.
A New Approach is Needed
To overcome the triple threat of wasting time, unreachable volume, and wide variety, new approaches to AI training must be explored. One such approach is called transfer learning, which uses a pre-trained model, from community-based data sets, and is adjusted to individual businesses as needed. To put it simply, this type of AI transfers knowledge from a previously learned task to the new task at hand. The model improves for everyone.
ThoughtTrace AI models are highly robust and trained on millions of documents across multiple sources. By leveraging community-driven datasets, the AI learns without limitation to one party, then grows and develops apply to future contracts. It goes without saying that every customer’s environment is unique and extremely secure.
Building your own model may provide an increased level of control and customization but as alluded to above, this will lead to a biased model even with millions of documents. A siloed solution will be much more likely to fall prey to AI pitfalls than community-driven models. The benefits of participating in a community-driven model platform, like ThoughtTrace, go beyond just data. All feedback and enhancement requests from industry leaders enhance the product for everyone. Thus, our customers are continuously tapped into innovative, validated, and high-performing models to fuel their contract analysis and intelligence.
At ThoughtTrace, we take pride in this approach to model development and data science. We believe it offers a distinct competitive advantage in delivering the most accurate and generalizable models possible, iterating quickly on customer feedback and improvements, and continuously expanding breadth into new use cases and contract types quickly and efficiently, which we will discuss in the second part of this article. ThoughtTrace customers do not have to ‘train’ the AI, and solution-specific configurations streamline adoption and migration. “ThoughtTrace works on day one” is more than a tagline – it’s reality, and we invite you to see for yourself!
To learn more about the benefits and drawbacks of ‘buy vs build’ and the different deployment models in the document analytics space – watch the webinar from ThoughtTrace CTO Joel Hron, “Playing a Leading Role in Digital Business Acceleration.” (originally published on CIO.com)
Part 2 Will Continue With:
- New Approaches to Contract AI Training
- How Community-Driven AI Models Work
- How ThoughtTrace Improves AI Training for Document Intelligence & Understanding